Some time ago someone at work asked me if I know anything about data mining. I replied that I sure do. Hell, I almost wrote a thesis on automated blind database integration. It was actually quite fascinating – we used modified TF-IDF scoring algorithm to discover which columns in which tables are semantically similar. Unfortunately my mentor got really sweet job at Oracle and left academia. That’s how I ended up doing hyperspectral imaging.
I figured that nothing the business world could throw at me would be as complex as the problem I dealt with – ie: “here are two databases, we know nothing about their schemas – now merge them”.
Little did I know that in the world of asset based lending, and accounting “data mining” roughly translates to “converting various files into excel format”. And of course you don’t even get to touch the database – oh no! You get a long flat file regurgitated by the client’s reporting system usually in a PDF format. Of course most of this data is designed for printer output – meaning pages the data into sizable chunks, and fits them with headers, footers, and all kinds of additional human friendly bullshit.
If you get lucky and get a text file, you can hammer it with awk or perl and get it formated into a nice csv format that can be then imported into excel. If you get a PDF, you are kinda fucked.
Fortunately people have devised software for this kind of work. I’m currently using Monarch Pro which is essentially an adjustable sieve for data files. You get to specify the shape of your data (it can do some primitive pattern matching, but not regexps cause that would actually make sense) then shake it an an excel file should fall out. Unfortunately just like in a real sieve you can only adjust it in a limited way. For example you can only have 1 distinct class of collected data per file, and that class must be represented as a single line/row. Let me show you:
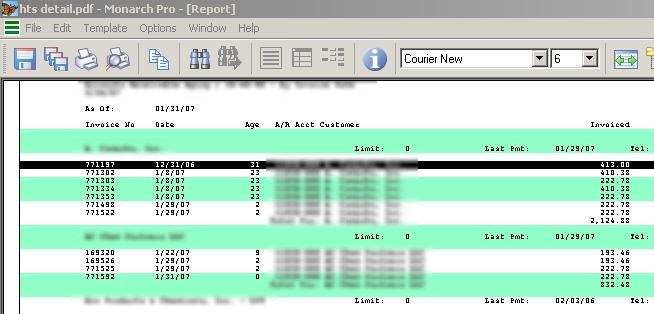
In the image above you can see a PDF report opened in Monarch. I blurred company names and other info for obvious reasons (not that you would get much out of this anyway). As you can see the file has headings, information lines, subtotals and etc all over the place. But the actual data can probably be best represented by the highlighted line. It can be used to create a “template”:
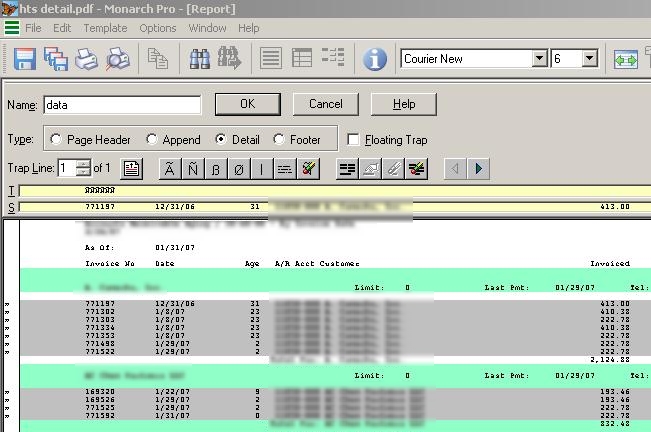
As you can see, we are creating a “detail” template. You can only have one detail template which is retarded IMHO but oh well. First thing we do is we tell Monarch how to find out which lines are significant. In this case it is simple. Each record line that contains actual “meat” starts with an account number. So I simply make Monarch grab each line which has 6 digit numerical string in that specific position. You can do this sort of pattern matching using the little buttons. The accented N means any numerics, the A means any literals, beta means blank spaces, and empty set means non-blank characters. Of course you can’t do regexps because that would actually be useful, and we can’t have that in a software designed for a business sector.
Now you define fields by highlighting them in the yellow box. Once your done your detail template should look something like this:
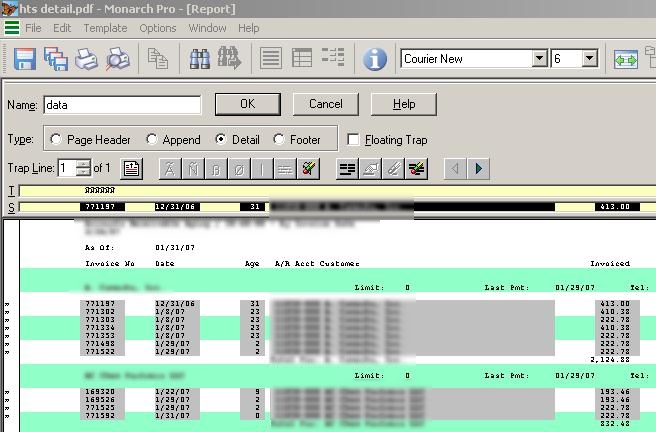
Of course there is some data around the “detail” that we might want to capture. Pay attention now, because this is the only thing in Monarch that I didn’t intuitively get at the first try. You can create what they call “append” templates. What they do, is they incorporate the data found on a given line into the “detail”. The fields in the append template will become columns in your finished table, and will be repeated down as needed. I will show you exactly how this works. First let’s make an “append” template. It’s done the exact same way – you highlight a line, say “New Template” and then provide some pattern matching hook and define fields:
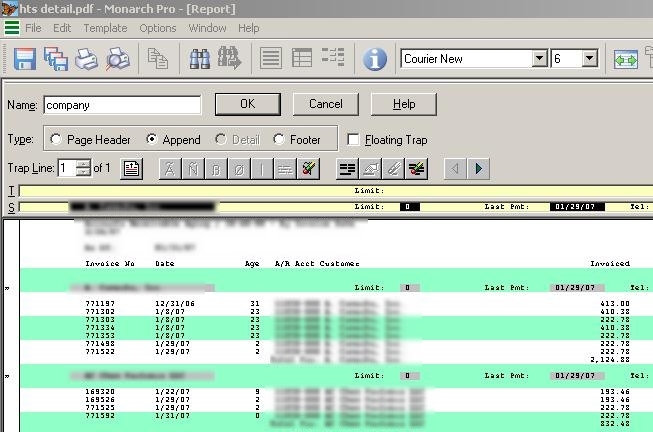
Here my hook is the word Limit repeating on each subheading in the exact same position, and my fields are the company name, the limit value, last payment and etc. Once we have all the templates set, we can switch to the table view and see the fruits of our efforts:
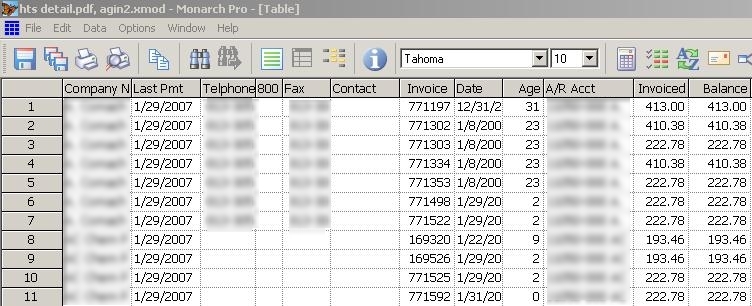
As you can see, the append fields, became columns and their values get repeated downwards for each “detail” row associated with that append block. We can now export it into a range of different data formats, out of which Excel is probably the most desirable for the business people.
There is one thing I haven’t figured out with Monarch yet. How to include subtotals in the table. Underneath each block of data in my file, there is a company subtotal. It does not make sense to capture this info as an “append” because I don’t want to see it repeated.
It also doesn’t make sense to include it in detail, because it does not conform to the detail format, and will throw off my pattern matching. If you could have more than one detail template I would probably be set, but you can’t.
So I guess there are two choices here – either leave the totals out of the file completely (after all they can be automatically generated by excel anyway) or tweak your detail template until it includes the totals.
I guess the moral of this story is that if a non-technical person asks you if you have any experience in data mining, it usually means they need someone to convert their PDF files into excel – and not to extract and merge data from relational databases. :|
[tags]monarch, data mining, data parsing, data conversion, excel[/tags]
Didn’t get to read the entire entry yet (will do so later today), but too bad that Koeller left the MSU. Great for him though.
just curious – have you tried ps2ascii or pstotext? found info here
http://www.postscript.org/FAQs/language/node36.html#SECTION00031100000 0000000000
acroread -toPostScript file.pdf && ps2ascii file.ps > file.txt
Miloš – yeah, it’s awesome for him. Sucked for me though. :|
Mirko – yeah, I tried that. You can get decent results out of very nice files, but more often than not, you get a jumbled mess unfortunately. As you can see in the pictures these files usually include loads of meta-data that does not need to be in excel and in fact gets in the way. Ps2Ascii grabs all of that. Monarch and similar tools give you much more control of what ends up in your output file, and what gets dropped.