Back in March, I more or less definitively resolved my private journal writing problem when I created MarkdownJournal.com. I made it primarily for myself and so it was designed to scratch all of my particular itches. It was made to be a web app that has a decent mobile interface so I can add entries whenever and wherever I am. I made it use Dropbox as a back-end so that I would have direct, file system access to my journal files from any machine I own. I built it to use Markdown so that I could edit the source files with any text editor if and when I needed to.
The only issue it didn’t really address was reading the damn thing. It turns out that sometimes you just want to go back and read what you wrote, and I didn’t actually put that functionality into my app because I didn’t really want to host or cache anyone’s personal writings on my server. I always imagined my app being just a web-editor front end for the files you store in your private Dropbox account. I figured that if you wanted to read your journal you’d just go to the source files and read them. Of course based this assumption on a survey I conducted on users of the application with the sample size of: me.
Dogfooding guys! Haven’t you heard about it? It means you build a tool for yourself and you don’t give two shits about users that aren’t you. Or something like that.
Anyways, turns out that’s actually not how I was using my journal.
My private journal happens to be much like this blog, just more boring, and more concise because I don’t explain things or even attempt to be coherent half of the time. It also contains much more of Aubrey Plaza (massive celebrity crush at the moment, don’t judge), Warhammer (so I’m collecting a Skaven army now because I apparently hate having money in my wallet) and randomly terribad ideas (what if cats are natural plane-walkers and when they purr the resonance actually shifts the reality according to their unknowable but likely sinister agenda). I also occasionally paste in links or code snippets into my entries when jotting down ideas for possible future projects (though I’m to lazy to actually implement even a fraction of these). Hell, sometimes I even put pictures in there.
Markdown makes this easy, but reading files with links, code snippets, and image tags can become a little tedious. Often I’d actually render the entry into HTML before I read it just so that all the links and markup would look the way it was supposed to.
At one point I got tired of manually converting the files all the time, so I wrote a nifty script that would grab current month’s journal file, run it through pandoc and then open resulting output in a web browser:
#!/bin/bash
PAGE_TITLE=$(date +"%B-%Y")
# Set these environment variables to make it work on other systems
[ -n "$JOURNAL_BROWSER" ] || JOURNAL_BROWSER=links
[ -n "$JOURNAL_DIR" ] || JOURNAL_DIR=/home/luke/Dropbox/Apps/Markdown\ Journal
[ -n "$JOURNAL_PANDOC_OPTS" ] || JOURNAL_PANDOC_OPTS="--section-divs --title-prefix=$PAGE_TITLE"
# cygwin users - link your dropbox folder in cygwin file system - like: /foo/bar
# use the unix style path in your variable - the script will translate later
# you will need windows version of pandoc since cygwin doesn't have it yet
FILE=$(date +"%Y-%m.%B.markdown")
if [ -f "$JOURNAL_DIR/$FILE" ]; then
# Make sure the script still works under cygwin with windows version of pandoc
if [[ $(uname -s) == "CYGWIN"* ]]; then
# translate paths to windows ones for pandoc.exe
JOURNAL_FILE="$(cygpath -aw "$JOURNAL_DIR")/$FILE"
JOURNAL_STYLE="$(cygpath -aw "$JOURNAL_DIR")/style"
JOURNAL_TMP="$(cygpath -aw "/tmp")/$$.html"
else
# use normal unix paths
JOURNAL_FILE="$JOURNAL_DIR/$FILE"
JOURNAL_STYLE="$JOURNAL_DIR/style"
JOURNAL_TMP=/tmp/$$.html
fi
# convert file
if [ -f "$JOURNAL_STYLE" ]; then
pandoc -s "$JOURNAL_FILE" -H "$JOURNAL_STYLE" -o $JOURNAL_TMP $JOURNAL_PANDOC_OPTS
else
pandoc -s "$JOURNAL_FILE" -o $JOURNAL_TMP
fi
echo $JOURNAL_TMP
# open in a browser
eval "$JOURNAL_BROWSER" '$JOURNAL_TMP'
else
echo Sorry, no such file: $JOURNAL_DIR/$FILE
fi
It’s all pure bash. I know I should man up and switch to zsh one day but… Well, I know bash kinda. And I do stuff like this in it, so it works for me most of the time. As you can probably see I went out of my way to ensue the damn thing worked on Mac, Linux and also Windows (via Cygwin). I’ve been using that for a while. I even had a nifty trick which would exploit pandoc feature set to inject a custom stylesheet into the output files so they would be rendered according to my specifications.
But, alas having a dedicated reader was a bit limiting. So I decided Markdown Journal needed a built-in, native reader feature. One thing I was adamant about though was that I didn’t actually want to cache or save anything on the server. In essence I didn’t want any user content touching the file system. I figured that the only way to do this is to slurp the entire file into memory, then render it and throw it all away when the user leaves the page. it turns out that in Sinatra rendering markdown formatted strings is actually super easy:
get '/read/:file' do
# make sure the user authorized with Drobox
redirect '/login' unless session[:dropbox]
# get DropboxSession out of Sinatra session store
dropbox_session = DropboxSession::deserialize(session[:dropbox])
# make sure it still has access token
redirect 'login' unless dropbox_session.authorized?
client = DropboxClient.new(dropbox_session, ACCESS_TYPE)
temp = client.get_file(params[:file])
erb :read, :locals => { :content => markdown(temp) }
end
Note that majority of that block above is just house-keeping and access control code. The relevant lines are #13 where your journal file is actually read into memory and #15 where it is rendered onto the page. That last line is especially interesting because it does a lot of work. It converts the markdown formatted string contained in the temp variable into a HTML string, and assigns it to the :contents variable. Then it passes it to an e-ruby template which is rendered onto the page. At no point is anything saved to the disk.
Granted, this is probably not the best way to do this and it definitely wont scale in the long run but somehow I don’t expect my little app to explode and become mainstream. For one, the pool of people who both enjoy markdown, have a dropbox account and are in the market for a simple journalling app is very, very limited.
If you log into Markdown Journal you will now see links to hour past journal entries listed right below the input box like this:
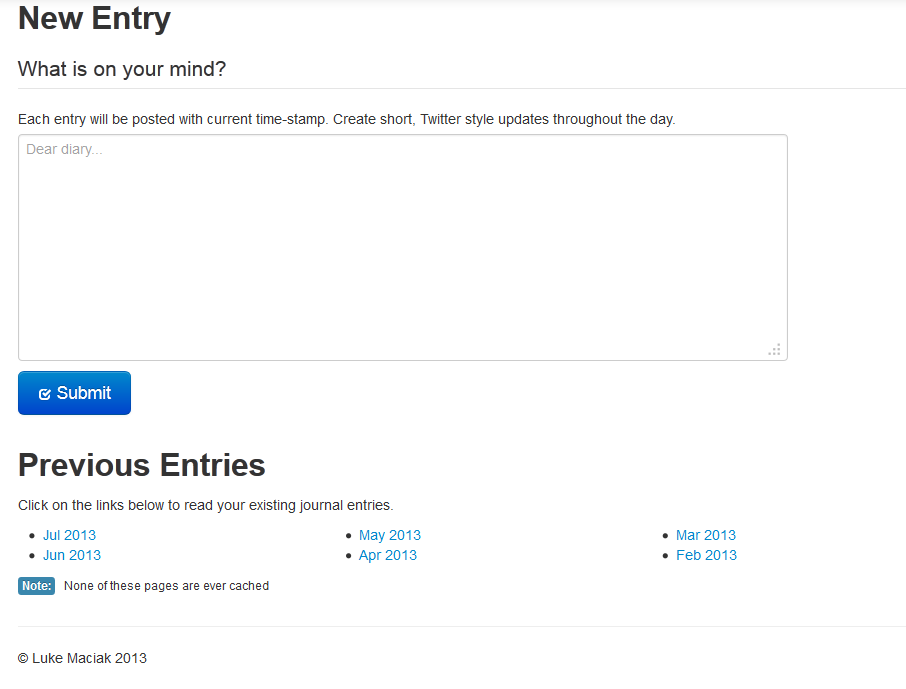
Reader Feature
The way I enumerate these is actually very simple – I use the metadata dump from Drobpbox to get a list of all the files in the Markdown Journal app directory (remember, it only has access to it’s own dedicated folder – not all of your Dropbox) like this:
client = DropboxClient.new(dropbox_session, ACCESS_TYPE)
list = client.metadata('/')
@files = list['contents']
Then I render the bullet point list like this in the e-ruby template:
-
<% @files.reverse.each do |file| %>
<% if (file['path'] =~ /^\/[0-9]*-[0-9]*\.[A-Za-z]*\.markdown$/) == 0 %>
- <%= file['path'][/\.([A-Za-z]*)\.markdown/, 1][0,3] +' '+ file['path'][1,4] %> <% end %> <% end %>
This is really concise due to the fact that much like in Perl, regexps are handled natively in Ruby. As in, there is no need to wrap them into strings and double-escape everything. If you don’t speak regexps let me explain these. The first one matches anything that:
- ^\/[0-9]* starts with bunch of numerical characters
- -[0-9]* followed by a dash and some more numbers
- \.[A-Za-z]* followed by a dot and some alpha characters
- \.markdown$ followed by .markdown which is the last thing on the line
In other words, match only files that follow the naming convention used by Markdown Journal which is YYYY-MM-Monthname.markdown. This might be slightly too generic (I’m not restricting the length of the numerical strings) so it might possibly match something that’s not a journal file but so far it worked. if anyone has suggestions on how to improve this, I’d love to see your take on it.
The second regexp pretty much just extracts the month name: give me the string of alpha characters sandwitched between two dots immediately followed by the word markdown more or less. Then on top of that I only grab the first three characters of that result to save space. It doesn’t really matter when viewed on a desktop, but in the mobile layout long month names like “february” would wrap to the next line screwing up the alignment.
TLDR: Markdown Journal has a new feature that lets your read your journal entries.