Some users are like little children or small animals: they require constant supervision, hand holding and care, else they may end up hurting themselves or damaging company property. Who are these users? Well, typically they are white collar office workers who have been using computers as their primary work tool for at least a decade or more, and yet still have absolutely no clue how to operate them or how they work. In other words, the people who fill up the help desk queue with tickets every single day of your life.
They should not be confused with Power Users, or as we call them in the business “professionals who treat their job seriously”. IT people don’t get to interact with these folks frequently, because frankly, they do not need hand-holding and spoon feeding and therefore contact the help desk only in dire emergencies, their tickets get quickly escalated and resolved at lightning speed because they are helpful, informative and cooperative. Regular users are typically anything but…
Also, please note that when I talk about users I don’t mean folks who don’t know much about computers because they don’t use them all that much. For example if your work does not involve editing electronic files and using office suite and email then I wouldn’t expect you to be an expert. On the other hand, if you have been using Microsoft Word and Outlook on every week day from 9am till 5pm for the last 15 years the I’d at least expect you to know how to double space a document or set up an email signature. If you can’t do these things, and you have to call the help desk on average once or twice a week so that they can remote-in and do it for you, then perhaps you shouldn’t be in this line of work…
It never ceases to amaze me how many people in the business world not only do not know how to do basic day-to-day computing, but have absolutely no idea how computers and internet work in general. To them, computers are mysterious black boxes with magic inside, and networks are strange, almost supernatural hyperspace portals between computers that allow magic, gnomes and unicorns to pass through and make things happen on the internet. They hold strange, almost superstitious beliefs about technology that have no grounding in reality whatsoever. Today I would like to talk about these common myths and misconceptions.
#1: Hacking is magic
Mostly due to portrayal of hacking in popular culture, most people who work with technology every day have very distorted view of computer security. I think the conceptual model they are working from is that computers have these magical barriers (firewalls) that protect them from unspecified dangers, but which can be circumvented by typing really fast without using the space bar. In essence, no security system is safe and a skillful hacker can break into just about any computer in less than five minutes if he is good enough.
Typically around the end of the semester, I teach my students how to “hack” computers. I don’t really show them anything practical – I simply give them a quick overview of the workflow used by character Trinity in the movie Matrix revolution, which to this day is the only Hollywood production that managed to show real hacking. If you have missed the 5 second clip, here is a screenshot:
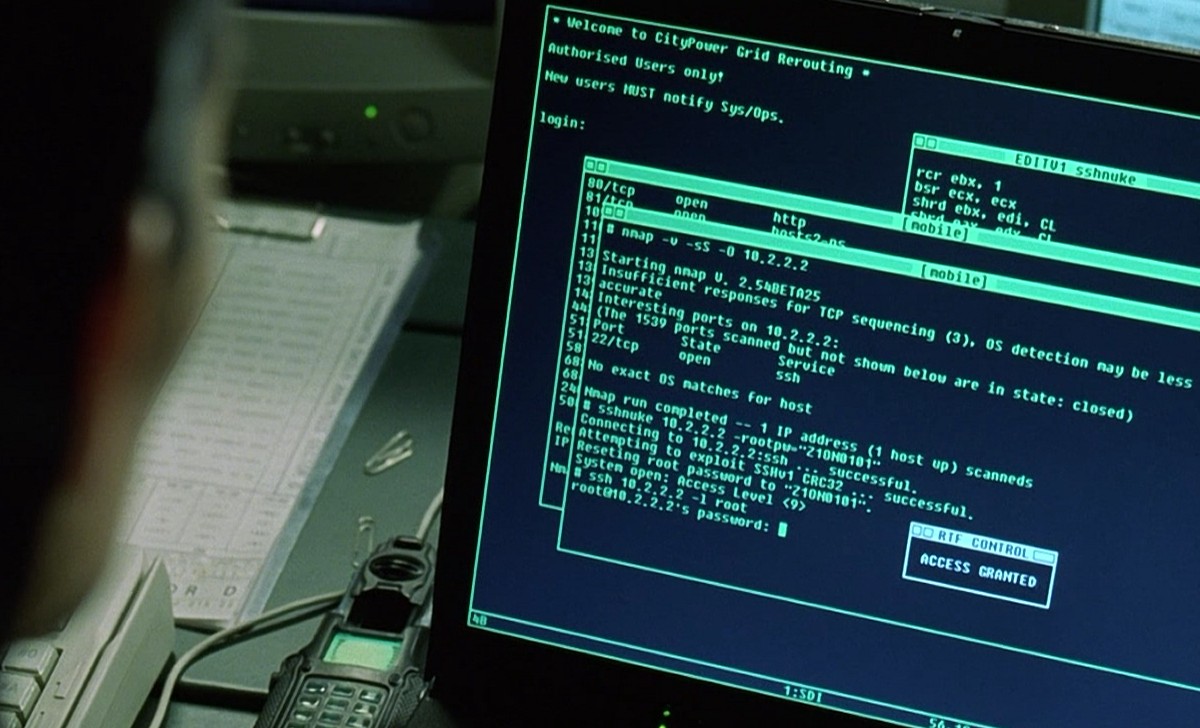
Trinity Using Nmap
Basically, you port scan your target, figure out what services are running on it, then you find one that is out of date, and exploit it. In the Matrix movie Trinity was able to break into a the power plant system, because the local sysadmin was an idiot and never updated the ssh demon on the internet facing machine. As a result she was able to run a 3 year old CRC32 exploit on the machine and get root with relative ease.
The important bit of this fictional scenario is that it was not magic. The computer system was compromised not because Trinty was a 1337 h4x0r but because it was not patched properly. The break in was not a result of hackers brilliance, but of bad IT policies a lackadaisical approach to software updates at the site. It was easily preventable and wouldn’t happen if the administrator did his job.
Just like many other types of white collar crime (like fraud for example) hacking works not because hackers posses some innate magical powers, but because laziness, incompetence or mistakes leave computer systems vulnerable. Granted, all software has bugs and potential vulnerabilities so it is technically impossible to build impenetrable systems. There is always a chance an inquisitive tinkerer can find a way to exploit some previously unknown bug or quirk to gain access. But even then, the actual exploit is a result of human (programmer) error and not a supernatural skill at typing really fast.
Not to mention that a lot of people imagine that when you are getting “hacked” it actually looks more or less like this:
It’s like a big battle of wits between the black hats and the white hats, and presumably whomever can type more words per minute will win. Or something like that. I don’t really know how people imagine it works. Honestly, if you are getting hacked, you probably won’t know until well after the fact. And if you do notice something fishy going on on your network, there is a very simple, robust solution that will thwart any hacking attempt with 100% success ratio:

Just Unplug
Despite popular belief, no hacker can actually get into computer that is turned off or not connected to the network unless he actually breaks into your house.
#2: Government can “hack” into everything
The corollary to the above is the unshakeable belief that the government, and especially CIA has access to super hacking tools which are above and beyond anything we could have ever seen in the private sector. Once again I blame Hollywood for this. This belief is on par with the notion that US government has access to super-advanced alien technologies recovered from the supposed Roswell UFO crash but for some strange reason refuses to use them.
The truth is that governmental agencies us the same shitty software we use in the private sector. Most of the good security tools are either open source, or commercially available world wide. The proprietary, custom spy stuff they have is likely just as shitty – especially considering it was most likely written by lowest bidding contractor, on a shoe tight budget and with an aggressive deadline. Actually, maybe I’m too harsh on governmental projects (but seriously, have you seen some of the web apps hosted on .gov domains?) – there are very likely some very talented and high paid teams working on the mission critical stuff for intelligence agencies and military.
Still, I don’t think it is possible for them to have some mega-hacking tools for the simple reason that “hacking ain’t magic”. We already established that it doesn’t work that way. Furthermore, any security related technology developed in secret by the government is likely going to be also independently developed in the private sector around the same time. The security world is interconnected and people everywhere work on similar problems, and come up with similar solutions. This is why most computer scientists are vehemently opposed to software patents.
Most computing problems have a limited number of optimal solutions. Very often researchers working independently converge on very similar solutions. Computer algorithms are not necessarily inventions, but rather discoveries. It is probably best to think of them as of mathematical formulas or laws of physics.
Recently this myth has flared up with the big news stories revolving around the PRISM surveillance program. But that program never involved superhuman “hacking”. It involved corporations willingly giving intelligence agencies access to their servers.
#3: Everything is a virus
Most people who fall into the non-power-user category are completely incapable of identifying malware. Or rather they tend to attribute typical non-malware, user errors or hardware issues to malicious viral activity, and ignore actual infection symptoms. I guess they assume is that a virus is supposed to do something unusual: for example print messages on the screen, play sinister audio clips and etc. This is typically reinforced by intro level technology courses which like to talk about the history of malware and showcase some of the early viruses that were written primarily for the proverbial LULZ. These days malware is primarily written with profit in mind: either used to deliver advertising as payload, or to create bonnets which can be utilized in various ways.
Things like this ought to be common knowledge considering the proliferation of malware on the internet, and the frequency with which the users pick it up in the wild. But alas, it is not. Let me run you through some examples that I have encountered in my travels just to give you an idea how a mind of a typical user works:
- Screen is upside down – definitely a virus
- Strange popups and redirects – business as usual
- Accidentally associated Word files with Adobe Reader – totally a virus
- Antivirus & firewall disabled and most executables crash – business as usual
- Battery status LED blinking red – OMG virus!
In other words, anything that seems strange or out of the ordinary (to them), is immediately labeled as virus. A more mundane glitches, crashes and nuisances are typically ignored and attributed to the incomprehensible and capricious nature of computing devices. Why there are popups everywhere? Who knows, the inner workings of a computer system are impossible to understand.
Typically, when a call comes in about a virus (singular), it is safe to assume the problem is anything but. The exception to the rule are the scareware infections. These are easy to identify because they typically claim the user’s computer is infected by hundreds of viruses.
#4: Internet research requires “computer skills”
Google is a company that was made famous by its radical approach to user interface. At the time when most companies aimed to fit as much information on their landing page as possible, Google left theirs bare save for a single functional element: a text box. To this day this type of interface remains one of the most intuitive, and user friendly interfaces. You are looking for something? Type your question into the box and hit search. Don’t feel like typing? Speak your query then – Google has semi-decent speech processing as well. And as soon as you do, a list of relevant web pages pops up, inviting you to click and explore or revise the search. I can’t imagine simpler method of interaction between man and machine.
And yet, a lot of users can’t seem to wrap their heads around it. Or perhaps they don’t want to. I can’t tell you how many times I had friends and relatives call me to ask my advice on a computer problem. Majority of these issues are resolved by simply typing the symptom description or error message into Google and following the top link on the page. In fact, this is likely what happens when you call someone for help with some random problem without bothering to do a tiny little bit of research first. Your friend will literally type what you say into Google and proceed to read off the solution from the first or second link on the page.
If you done some basic research and followed easy steps (such as rebooting, downloading updates, running virus scan, etc..) and got stuck on a technical fix that, for example, requires editing windows registry (or typing commands into the terminal) then it is a completely different conversation, mind you. That’s actually perfectly acceptable and reasonable point at which one ought to seek technical help.
But requests for assistance with Google are not limited to technical problems. Quite often people ask me for help doing basic online searches that have nothing to do with computers or even with electronics. For example, a someone recently asked me to find out what is the best kind of propane grill out there.
If my name was Hank Hill this would be a legitimate and reasonable question. If I was an American dad who actually owns and uses a grill this would be a legitimate and reasonable question. If I ever voiced an opinion in the propane vs charcoal vs wood debate, this would be a legitimate question. If I ever bragged in a manly way about my grilling prowess, this would be a legitimate question. But I am none of these. I treat barbecuing mostly as a spectator sport – which in my case means I stand back and let other people talk excitedly about it while I try to figure out why they find it so interesting. Why was I chosen for this task? Would you care to take a guess?
Because I am a computer guy, and therefore I am good at searching things on the internet. Apparently my vim skills, and my experience in Python, PHP and Ruby somehow make me really good at typing things into a box and reading things off the screen. Unlike troubleshooting computer problems which can sometimes be little tricky, searching the internet for non-technical information (such as customer reviews) is something anyone should be able to do. The only skills required to use Google are:
- Ability to type words into a box
- Reading comprehension at grade school level
Once you have these two skills down, the rest is just trial and error. By that I mean, typing in a general search query, evaluating results with respect to relevance and narrowing down the query by adding or removing keywords if needed. You do not need to be “good at computers” to do this. In fact, you don’t even need to be smart to do it. It’s basic pattern recognition.
I honestly don’t know why people do this, but I have a few theories. One is that users who are otherwise intelligent and well adjusted human beings simply turn off their brain as soon as they find themselves in a vicinity of a computer as a defense mechanism that protects them from accidentally learning something new about the tool they use for work every day. Either that or they are simply lazy and they use their “computer illiteracy” as an excuse to get someone to do the research for them.
I don’t know why this happens, because in the movies web search works about the same as in real life only default font sizes in browsers are super huge and no one ever uses Google or any other existing search engine.
#5: WWW goes in front of everything
The www subdomain is kinda weird these days. Back in Pleistocene when the Internet was still young we didn’t know that the World Wide Web will become so big and important. It was just something that Tim Berners-Lee cooked up, and which while really cool was mostly geared toward creation of interlinked documents. But if you needed to transfer non-text files for example there were much better ways to do it, than try to shoe-horn them into HTTP packets. We hat FTP and Gopher for example.
Quick aside, did you know that there is still about 160 Gopher servers on the internet and that you can actually still browse the Gopherspace using the Lynx web browser? In fact, browsing Gopher servers with Lynx is actually more fun than trying to browse the web with it. If you want to try it for yourself the Floodgap is a good place to start. Just do:
lynx gopher://gopher.floodgap.com/1/world
Anyway, the web wide world was a much different place back in the days when Gopher was a protocol and not an annoying garden rodent your dad complains about all the time. We sort of imagined that most internet places would want to set up service specific subdomains: so for example if you wanted to Gopher around you’d go to gopher.example.com. If you wanted to upload some files you’d go to ftp.example.com. And if you wanted to check the website, you’d go to www.example.com. It made sense at the time.
Then of course gopher became an animal and web became a big thing. All people wanted to do was to browse it, and web designers quickly realized that if you really wanted people to download a file, you just linked to it. It was much clearer and easier than posting instructions on how to access the FTP or Gopher server and hope the user doesn’t fall asleep or get bored and return to browsing porn halfway through reading them.

Gopher – No Longer a Protocol
But we ended up with the www subdomain attached to a lot of web addresses. It is sort of like the tail bone of the internet at this point – mostly useless, legacy thing that some people argue helps us in some way with balance, posture or some shit like that. The www subdomain is still typically the default location for the web server, but it doesn’t have the same importance as in the past.
Today, most webmasters set up their DNS records so that you don’t actually have to type it in. For example, it doesn’t matter whether you type in www.terminally-incoherent.com or terminally-incoherent.com into your address bar – you will still get to this site no matter what. Some web browsers will also helpfully add the www for you in cases where it makes sense so you don’t really need to worry about. We as web designers don’t even want people to think about the three dubs anymore.
But there is a cadre of middle aged users who were introduced to the web at the height of the .com boom who will religiously type in www in front of everything. Especially subdomains. So for example, webmail.example.com becomes www.webmail.example.com. Or even worse: imap.example.com is now www.imap.example.com.
These folks are adamant about their dubs, and they refuse to listen to anyone about it. Hell, they will fight to death with senior IT dudes over their inalienable right to type www in front of everything. And when I say “fight to death” I mean like “pistols at dawn” style (side note: apparently when you run out of bullets it counts as a draw). As a result we ended up putting wildcard DNS records for every subdomain.
#6: Memory is storage
Conceptually, this is not a very intuitive thing to grasp. I can kinda see why people get confused about this. Computers have two types of memory: main memory where you temporarily store running programs and currently processed data, and secondary memory also known as mass storage where you keep all the illegally downloaded mp3’s and porn. The distinction between these two types of memory is probably one of the most useful, and enlightening things you can learn as a casual computer user. Groking it gives you really good insight into how performance of your computer is actually measured, and what the specs listed on the computer box actually mean.
A user who understands the distinction between main memory and storage will no longer be baffled by the fact that a really large hard drive doesn’t speed up his computer, or that no matter how many rams you jam into a computer case it will not increase it’s capacity to store your pornography and word documents.

I have this many rams, is this enough to store all my vacation pictures?
This is actually, really, really, really difficult to teach. I spend a lot of time trying to drive this home using all kinds of metaphors: like the brain for example. You have short term memory that evaporates in seconds, and long term memory which lasts for a while but sometimes retrieving from it is slow. Memory is like your desk, and storage is like the filing cabinet next to it where you put the files once you are done with them. RAM is what you hold in your hands, HD is your backpack. I re-iterate, re-iterate, re-explain, show pictures, draw diagrams and constantly return to this topic in just about every lecture (because it ties into so many things). And without fail, there is always one student that walks up to me at the end of the semester asking now many rams they need to store a lot of movies.
#7: The number of files on hard drive has impact on performance
This should technically be part of #6 but it is so common that I decided to give it entry of its own. Partly because this misconception is perpetuated by people who don’t even know about RAMs. You can usually make people who internalized #6 relatively happy by telling them to download a few rams from the interwebs. While the website doesn’t actually do anything, it provides users a with a pleasurable progress bar feedback which causes a placebo like effect, and often alleviates the “my lap top is slOw for no raisins” problem.
For some strange reason however large percentage of population think that cluttered hard drive negatively impacts performance in a huge way. I’m not sure if this is a throw-back to the good old days of non-journaled file systems when fragmentation was a huge issue, or just a conceptual glitch. I guess I can see how someone could think of a computer as a room, populated by little gnomes that do magical things – and if you don’t keep it tidy and delete unused files it becomes a junk pile, causing the gnomes to get lost while they frantically run around trying to find your shit underneath all the garbage… Or something like that.

And this is why they call it the motherboard.
I mean, yes – a hard drive that is 99% full, and very fragmented will slow you down a bit. But you only take the performance hit when you are reading or writing to the drive. If you have enough RAM, your computer should chug along relatively smoothly unless you open up a million things and force it to page to disk. And of course, once you start paging, shit will be slow no matter what because disk is slow.
This means that no matter how many files you delete from your hard drive, the performance is not going to improve much. There are many factors that degrade performance, but having too much porn and illegal music on your hard drive is not one of them. Typically the biggest culprits are resident processes that like to stay in memory and sap CPU cycles at all times. Despite what many inexperience users think, antivirus suites with big brand names like McAfee and Norton are absolutely terrible in that aspect: uninstalling and replacing them with less memory intensive alternatives will typically increase your performance at least ten fold, if not more.
#8: Downloading is catch all term
Users really, really, really like to download stuff. Most of them are not entirely sure what that word means, but for some reason the really like to use it in every sentence. On an average helpdesk call, you can expect the word “downloaded” to be used about 8-10 times, in different contexts meaning different things. Because fuck consistency, and fuck communication! DOWNLOAD ALL THE THINGS!
To help new help desk drones we have created the following chart to help you understand the different ways in which this word can be used:
Downloading: The Definitive Chart
- Installing (software) – I downloaded Microsoft Word from that CD you gave me.
- Installing (hardware) – A technician downloaded some rams into my computer.
- Un-Installing – I downloaded it off my computer to make more space.
- Uploading – I downloaded a file via the web portal, see if you got it.
- Submitting – I downloaded that web form.
- Filling out – I downloaded that web form with my information but it won’t download.
- Attaching – I downloaded it as an attachment in an email I sent you.
- Saving – I chose Save As and downloaded it to My Documents.
- Downloading – I uploaded fox fire from the website but now it wont download.
I guess the most important thing to remember is that users will never, ever use the word “downloaded” when they want to say they have obtained some file from a website. They will typically use the word “uploaded” for that. Every other computer related action that in any way involves networks or magic will be branded as downloading. Don’t question it – just refer to the chart, and try your best to guess what they meant. Follow up questions as to where the file was initially, where it ended up and where it was supposed to go, will let you determine the context.
#9: Computer Science courses teach you how to repair computers
Every relative I have thinks that what I learned in school is essentially computer repair. I mean, it totally makes sense, right? Computers are so complex and magical that you need to spend 6 years in school and get a master’s degree in Computer Science in order to even begin to repair them. I bet a lot of folks seriously think that dudes that work at Geek Squad all have fancy college degrees in computer science or something.

Obligatory Meme
The truth is that Computer Science is as much about computers as astronomy is about telescopes. They are tools and the technological back-pinning of the science which in itself is more of a study of information, algorithms and discrete systems than anything else. It is a science – an academic discipline that is very close to mathematics, but while Math is typically pure abstract theory, CS has some non-theoretical domains in which you get to apply the mathematical models and formulas. A good CS program is not focused on teaching you how to program, but rather forces you to learn programming in order to be able to do more interesting things.
But alas, an average user who can just barely manage to turn their computer on in the morning without having a panic attack is not going to know about this. Why? Because they actively avoid learning anything – we already established that, haven’t we? If you close your mind to new information, you are not being a productive member of the society – you are the useless log of flesh we have to drag behind us as we move forward.
#10: Macs are better for graphics
I think the marketroids at Apple are still patting themselves on the back over this particular myth. It is almost uncanny how deeply this baseless assumption got assimilated into public consciousness. I guess, once upon a time, back in Pleistocene this might have been true. At some point in history, Apple probably did have a slight edge in this department with specialized hardware and optimized software and built in displays they could claim were custom calibrated for high quality. But that was long time ago, and even then questionable.
Today Macs use the same off-the shelf hardware you can find in your PC so there is no edge there, unless you get one of them Retina Display macs. The software graphic designers use is the same on both platforms, and it is made by Adobe, not apple. In fact, Adobe and Apple are not on best terms these days. They certainly have no incentives to make the Mac ports of their famed design suite run any better. In fact, they probably stand to profit if it runs worse than the PC version.
Granted, there are tons of reasons you would to get a Mac computer: like Unix under the hood, or the fact that it is not Windows 8 for example. But the graphics thing: that’s simply not true. There is nothing in OSX and Mac hardware that makes it inherently better at graphic design. Well, except the Retina displays maybe.
#11: Zoom and Enhance
Speaking of image processing, here is another thing that Hollywood totally ruined, and turned into a joke:
This is especially infuriating because it is super easy to test this at home: just open an image, and zoom the fuck in. At some point, the image becomes a mosaic of squares. Each of them is a single color dot representing a pixel at the resolution at which the picture was taken. A one megapixel camera will take a picture that contains 1 million of such dots, and not a single one more. Each dot has only one data point of information (other than its position in the grid): color and intensity. When you zoom into a photo, all you are doing is making the pixels bigger – each dot of the image, becomes a number of dots on your screen. At some point they become visible to the naked eye as ugly squares.
You can’t zoom in beyond that though. You can’t enhance a pixelated image because there is simply no information there. You only have the pixels that are already in the image and nothing beyond that. This is the technical limitation inherent to bitmap imaging – it is how all digital cameras work and there is nothing you can do about it. Enhancing algorithms are not magic – they can potentially clean up a pixelated image and make it less blurry, but they can’t extract information that is not in the file.

Zoom In
The only way to get a clear image of a reflection on someone’s iris is to take that photo with a high resolution camera. A grainy, night vision shot from a gas station security cam is never going to have the resolution you need to do the kind of processing you typically see in Hollywood movies.
#12: I don’t have anything worth backing up
Every time I talk to users about backup strategies, they give me the same line: I don’t think I really have anything worth backing up on there.
This is of course a blatant lie. Well, maybe not a lie but just a misconception. The fact is you do have stuff on there that you would loathe to lose – you just don’t realize it yet. Do you know how I know? Because I like to play the game that goes like this:
“Hey, remember how you told me you don’t do backups on your computer because you don’t have anything important there? Well, yesterday when you dropped it of at my place I just straight up re-imaged it without saving any of your stuff.”
Then I enjoy about 15 minutes of cursing, yelling and crying before I tell you I was kidding and that I actually backed up all your stuff. And if you didn’t have anything important on your hard drive you wouldn’t be whining, crying just now. You do have shit on your computer you don’t want to lose. Everyone does. This includes pictures, documents, locally saved emails, bookmarks, saved passwords even configuration details. If you do as little as backing up your Chrome/Firefox profile folder, it actually saves incredible amount of grief and pain later on. Instead of trying to find all your favorite sites again, and remember passwords to the more obscure ones, you can have your browser open up to your last session as if nothing has happened.
If you really have nothing to lose, then you should have no problem wiping your hard drive and re-installing the OS now. If all your stuff is in the cloud, and you have nothing saved locally that is not synced up to some remote server then you are all set – you probably don’t need to do backups. You can let your cloud provider and NSA mirror your shit for you. But as long as you save anything locally, backing up should be a habitual and involuntary reflex.
So, what are your favorite myths and misconceptions about computing? Let me know in the comments.
1. “recent files” is an actual directory in your system where you can store things. Later you’ll be able to open
that directory with the explorer.
2. Did you safe removed your usb key?
What? Oh, yes, I am safe, don’t worry
Also, a lot of wrong names even from the people that should know what they are doing: “I coded this little shell.” No, you didn’t, idiot!!! A script is not a shell
To be fair to the point of larger storage not speeding up the system, as you scale ssds up in size they get faster. Stupidly faster. Though, if a luser wanted to argue that point they would need to know what an ssd is….
At some point my girlfriend told me about lmgtfy.com when she was responding to questions from her mom, sounds like you may find it useful. Here’s an example and it offers link shortening right on the page for stealth shenanigans.
I almost died when I saw downloadmoreram.com, that is awesome.
Thanks for some laughs on a Monday.
So you’re saying hackers make their victims wear silly hats!
I think there is one caveat to this, but it’s about the NSA instead of the CIA. It’s almost certain the NSA has years or even decades of lead on everyone else, or at least on published knowledge, in cryptography. This has been apparent in their involvement in with SHA-1 and DES. They published SHA-0, quickly withdrew it, and then published SHA-1 with one tiny change, all without explaining why. Years later this change had been proven to be critical after SHA-0 vulnerabilities were found.
Similarly, the NSA was involved with IBM’s DES design in the 70’s. They made changes to the algorithm’s S-boxes for reasons that were a complete mystery to everyone else at the time. In fact, it was incredibly suspicious, as it could very well have been to introduce a backdoor. Note that the NSA had already been trying to convince IBM to shorten the key length to 48 bits, suggesting that they had, or almost had, the ability to crack keys this short at the time. Almost two decades later, differential cryptanalysis was discovered (publicly, anyway), and it turns out that the S-boxes had been designed with this new cryptanalysis technique in mind.
As another example, the NSA claims to have discovered public key crypto a decade before Diffie and Hellman publicly discovered it. There’s no evidence for this claim, though.
So it’s not that the NSA could easily hack into your computer, but they may uniquely have the ability to break some of the cryptography we commonly employ. Lucky for them they haven’t needed it much, because data carriers have been either willing or legally forced to hand over data unencrypted anyway.
@ agn0sis:
Apparently, safely removing USB keys is for wimps. Oh, wait… Why didn’t my file save? Computers are bullshit! :P
@ Everlag:
That is true, but your computer doesn’t get incrementally slower as the hard drive fills up. Which is typically what people think when the say: “Yeah, it’s been getting kinda slow lately – that’s probably because I have bunch of stuff on it I should probably delete…”
@ Mitlik:
You know, I actually was intending to link the lmgtfy.com in the web search section at some point, and then I forgot because I started googling for Hank Hill youtube clips. :P
@ Chris Wellons:
Good point, but yeah – encryption breaking is a bit of a far cry from Hollywood hacking scenarios. But yeah, I think I heard the story about DES somewhere before. Chances are AES may also be compromised. That said, if you willingly left a secret back-door in an encryption standard you use internally to protect national secrets then that is a bit of a security hole, isn’t it? I mean, if a vulnerability exists then it is only a matter of time before it becomes public (or semi-public) in some way.
So while NSA may have some back-hacks for crypto-hacking, it is only a temporary edge and to maintain it they will have to keep releasing these compromised algorithms into the public hoping they become ubiquitous.
@ Luke Maciak:
That’s actually part of my argument for why I think AES is safe from the NSA. The NSA itself uses it to protect their own secrets, up through at least Top Secret. They wouldn’t backdoor their own information. However, a co-worker of mine isn’t convinced by this argument. “The NSA isn’t in the business of keeping secrets, even including their own,” he tells me.
I like justfuckinggoogleit.com though it does require a little discretion in how you use it….
@ Luke Maciak:
I think I know where this comes from. Back in the Win95/98 days, the Windows UI would noticeably slow down if you had a large number of files on the desktop. This makes sense, since it’s got a bunch more sprites to plot. Since the average user would make no distinction between saving a file to the desktop and saving it anywhere else (if they’ve even got the idea that it’s possible to save a file anywhere but the desktop…), it’s a natural assumption that storing more files == slowing things down.
Some of these are hilarious, others are just sad. Also (and I’m not trying to be rude or a d*ckhead) I think you need to move jobs. Do not move to a Uni. It is worse. Tonnes of smart people that are only *really* smart at ONE thing (and the thing is rarely ever to do with computer). It will irritate you beyond belief. Every other month the IT dept at my Uni send out staff-wide emails with don’t click on such and such phishing email, bad things will happen yadayada etc. It’s hideous XP Just reading all that crap as an uninvolved person is irritating I don’t know how you deal with the actual idiots responsible for all that crap..
very nice article, well written as usual, though you seem to publish less and less?
apart from the fun factor that allows you to write humorous articles that resemble BOFH a bit it occurs to me that you are a bit unhappy at your job? ;)
one correction to the DES encryption claim: allegedly IBM had to hand out 16 bit of the Lotus Notes DES key to the NSA. They could crack 40 bit DES but not the full 56 bit (at that time in the 70s). To my knowledge there never was an escrow or limitation to that 48 bit referenced in Chris’ comment. Unless they have discovered a factorization method to find out the prime numbers used there currently is no known method to crack RSA, DH and similar encryption algorithms, provided your key is sufficiently large, e.g. 2048 or 3072 bit.
Re the current SIM card foulup: some companies were dumb enough to implement 3DES by simply repeating the DES key 3 times. Makes it obviously 3 times harder to crack ;)
I am not an IT professional, but I have a number of friends who are older people who are frequently baffled by the computer and its mysteries. My solution to the memory problem is to use the car analogy: RAM is like the engine, which makes it go, and the storage memory is like the trunk of the car, which holds things. That seems to work pretty well. It’s an easy analogy to expand, too, with thumb drives, external HD’s and CD’s as car-top carriers and trailers.
Also, I think a lot of otherwise intelligent people get overwhelmed by the sheer amount of information available at the touch of a Google search and so their pleas to you for help finding, say, the perfect propane grill, have less to do with the mechanism of performing a search and more to do with winnowing the wheat from the chaff and discerning the most trustworthy and reliable results. No-one wants to just follow the first result and then learn it was a bad choice.
@ regularfry:
That actually could be where it came from. Then again I’ve seen users who are way to young to have ever used Win95 make that mistake. Maybe they learned it from their parents though.
@ theperfectnose:
Heh, I part-time teach at a university so I do know a thing or two about that. Thankfully I’m not working for their IT department, but I used to be the webmaster for the cs dept when I was a grad student there. Fun times. :P
ths wrote:
Guilty as charged. Here is my list of excuses as to why my output is shitty lately:
– DOTA2
– Warhammer
– Steam Summer Sale games
– Lack of Sleep (due to the above)
– Random real life crap (getting teh flu, dental work, car problems, etc..)
– Laziness
Last few weeks I figured I might as well crank out one longer article per week than try to rush out 3 short ones that are like “oh, hai – this is what I typed into terminal today and I thought it was cool.” I figured that if I’m writing a post, and I suddenly get violently bored with it and try to get it over with as soon as possible so I can go do something else then I’m doing it wrong. Better put it down and come back to it later when inspiration strikes than try to power through and risk burn-out.
Oh, and the whole bitter and unhappy BOFH is more or less a comedic trope, isn’t it? I mean there is not a lot of comedy in going “my job is pretty ok, my users are actually pretty decent and my problem-children make up for being computer-illiterate by being really nice, friendly and thankful”.
That said, can I haz a job at Googles where I get to play with Pythonz or Rubies all day, and users are not allowed in the building? Cause I’d totally get on that… But it has to be local, because I don’t want to move away. :P
@ NMS:
Isn’t if funny that a car (a remarkably complex machine if you think about it) is the one piece of technology that everyone seems to understand – even people who don’t own or drive them. Back in the day, everyone and their mom used to have a VCR but no one save precious few knew how to set the clock on these damn things. Same people who had the forever-blinking 12:00 on their VCR would have no issues configuring or even re-wiring their car stereo. Go figure.
As for Google – yes, that’s exactly it. But that’s exactly my point: the ability to identify good results from bad is not a “computer guy” skill. It is critical thinking skill. Sure, the sheer volume of information can be overwhelming, and a lot of links will lead you to useless places but after spending a few hours with Google you should start to see patterns like:
– specific querries with carefully chosen keywords yield better results than generic one-word queries
– seo-spam can be often spotted at a glance just from the contents of link/excerpt
– certain websites are more helpful than others (sales sites vs forums / communities)
– etc..
About point #5: http://www.example.com is not a “subdomain”, it’s a hostname! “www” is the name of a computer that serves the webpages, and ftp is the name of the ftp server, and they live on the example.com domain.
Apart from the ones mentioned, this is my favourite myth about computing:
Is that like music that you downloaded after breaking into a stranger’s house and pilfering their laptop to download it with?
If you’re referring to that wishy-washy concept of ‘copyright’, you might be surprised to find that no court of law will uphold a criminal charge against someone for producing a copy of some data for their own private enjoyment on a computer that they have access to, because you simply can’t prove that there is an injured party, just as if I used another computer known as a ‘digital camera’ to make an image of a recent painting for me to look at later. The only people who have supposedly been convicted for ‘downloading illegally’ or ‘file-sharing’ had been fooled into pleading guilty to some obscure civil charge(s) using that fun old game ‘good-cop-bad-cop’.
Beyond that, even redistributing ‘copyright’ data for no commercial gain and without plagiarism, has been upheld as not only not a crime, but about as far from it as you can get, as almost everyone knows how fundamentally beneficial sharing is for a healthy society.
Number of files has impact on performance…
You don’t need to hit the 95%+ disk usage mark to hit this as a real problem. Get a spindle disk, NTFS format it, write a few 100,000 small sized files, and you start to get MFT fragmentation. Add low disk capacity remaining with very large numbers of files on the disk, and you get an MFT which spread across the disk. This genuinely does cause performance issues when doing any disk accessing work.
Microsoft even mention a performance hit with 300,000 files in a folder (http://technet.microsoft.com/en-us/library/cc781134%28v=ws.10%29.aspx ).
There is also a non-direct cause of “lots of files = bad performance” (again back in the good old days with spinning ATA disks). When you’re utilising large amounts of the physical disk you also get more chance of using a bad sector on the disk (assuming your average user has never checked for physical disk errors). This in turn can make CRC errors on file access, which can drop an old ATA down from UDMA into PIO mode which is horrific. We had this happen quite commonly in laptops at work, where the old disks were prone to physical faults due to users walking around with the laptops on. Fixing PIO mode issues became a major speed boost for our users.
Luke Maciak wrote:
Yes, exactly! I don’t understand the mentality that leads to I can change my breaks (upon which my life relies on being done correctly) but changing some things on a computer might cause some real harm. Maybe it goes back to the economists’ point that humans are horrible at judging risk.
@ regularfry:
Worse: Windows systems have a little trick to improve searching/opening performance of files in the various folders called “My Pictures”, “My Movies”, “Documents & Settings” etc. It’s called indexing and caching.
Unfortunately, if you have a lot of files relative to the computing performance of your machine (particularly RAM) that indexing slows you down a lot. Worse still, it can even prevent your system from booting: the system may run out of RAM before you even get to your desktop. “Too many files in My Documents and Settings” is a known issue with Windows XP for example.
Nice post. Loved it!
Being the huge Matrix fan that I am, I should point out, that hacking scene is from The Matrix Reloaded. Secondly The Bourne Ultimatum also shows hacking using nmap.
The state of the art in enhancing images is not quite as clear-cut as you make it sound in “#11 Zoom and Enhance”.
Yes, Hollywood has turned it into a joke, but statements like “it is super easy to test this at home: just open an image, and zoom … in” and “when you zoom into a photo, all you are doing is making the pixels bigger” aren’t quite the full story. Absolute statements like that annoy me almost as much as the stupid levels of zooming seen on film. That’s a shame as the main point you were making was good.
For still pictures, the comment isn’t far off: it depends on whether the image quality was limited by the number of pixels or the optical characteristics of the camera. If the latter (slightly out of focus, motion blurred, diffraction limited) then there may be things you can do but it won’t be much.
It’s where you write “they can’t extract information that is not in the file” that things get interesting – particularly if the file was a video. Video is a whole different issue. There is information in the file that’s not in a single frame. A good algorithm can merge information from multiple frames.
There’s a whole field of study called “superresolution reconstruction” which is precisely about extracting features that are smaller than one pixel in one frame of the original image.
Searching the web, I can find lots of scientific articles but not many demos. I did eventually find some from commercial sites (I’m not affiliated with any of these). So, with the caveat that commercial demos may overplay the utility of these techniques, have a look at:
Infognition’s introduction to superresolution
Infognition’s demo of different reconstruction algorithms
MotionDSP’s demo of their Ikena forensic tool
So, yes, when Hollywood zoom into the reflection of a face in a vase where the entire face was less than one pixel in the original image, they’ve lost touch with reality. However, when they enhance a vehicle’s number plate where the letters weren’t quite visible on one frame of original video (you could tell there were letters there, but not which letters), it’s not quite so unbelievable.
Another popular myth is that watching videos online doesn’t account for downloading data. Some people get really upset when they discover the opposite.
I remember my brother asking for my help because he couldn’t get a program to install. It was called Tree and it enabled “branches” of data folders and subdirectories. It was a 25 year old MSDOS program and he was trying to use it on Windows XP not knowing what it was even for!