Most seasoned programmers are keenly aware of the way different platforms encode line endings in text files. Novice coders and non-technical folk however are often taken completely by surprise by it. In a layman’s world the problem of line termination is a non issue. In print, line size is determined by paper size (or rather the printable area the page) and a lot of the software used to generate printable documents mimics that pattern. Word processors for example automatically wrap long lines to conform to the margin settings chosen by the user.
Even power users sometimes fall into the trap of forgetting how line terminators work. For example it is easy to look at the way scripting tools such as sed, awk or diff can rapidly edit/scan files on line-by-line basis, and be fooled into thinking that there is some sort of array like structure to text files. That you can just address, pull out or delete line at will without much processing. But this is not true. There is no line based structure to text files. A line break is nothing more than a set of non-printable characters.
The funny bit is that this set varies from one platform to the other. Windows encodes line endings as a Carriage Return character followed by a Line Feed character. Unixes usually use a single Line Feed. Why though? How come this thing isn’t standardized? Well, it has a lot to do with history and legacy applications.
It all more or less started here:

A Typewriter
Long, long time ago (sometime around the Precambrian era I believe) recently evolved humans have devised a rather primitive typesetting devices they dubbed “type writers”. These devices would use a mechanical lever system to allow the user to press a key, and cause a corresponding hammer with a movable type font mounted on it’s head to strike the paper through an ink ribbon leaving a permanent mark. These things became extremely popular because in addition to their utility as output devices, their weight and sharp edges made them efficient weapons against raptors and other kinds of predatory dinosaurs that I presume roamed the Earth back then.
Typewriters were very constrained by their output medium. They used either spools or single sheets of paper which were neither reusable, nor very robust. The complex mechanical array that moved the hammers had to stay fixed in a single position so the writable medium was the part that was to be moved and advanced as the output was generated. As you typed the paper would slide to the left by even, fixed intervals. Naturally there were only so many characters one could type in a sequence before running out of paper. Then one had to return the paper carrying mechanism back to it’s initial position (an action commonly referred to as carriage return) and feed a little bit of paper by turning a knob on the side (or perform a line feed operation). This was a tedious process and eventually, it was automated. Typewriters gained a “Return” key which performed both these actions automatically. They also usually emitted a little bell sound to alert the user that the spring loaded paper carriage is about to do a violent, startling jerk and slam movement.
Much later (around the bronze age) when humans invented computers and started thinking about ways of representing textual data in memory, these actions were codified as part of ANSI/ASCII character tables:
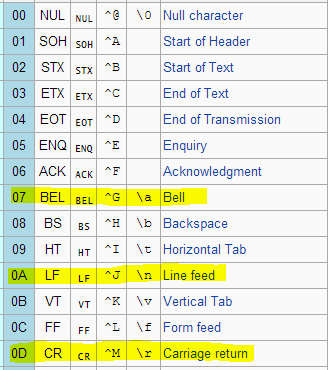
A selection of non printable ASCII characters.
Yes, there exists a bell character – a virtual descendant of the typewriter bell. Fortunately, our forefathers quickly realized how annoying that sound is and decided not to use it… much.
Why were these things even codified? Well, why not? Progress does not happen in huge leaps. It is usually a gradual iterative process. At the time the world was moving away from typewriters but not completely rid of them, or of the mindsets that came with them. Just like today’s old generations have trouble grokking the difference between digital information and physical objects, their grandparents had trouble shaking off the idea of feeding textual information into a computer without involving a typewriter of some sort.
Many early computers did not use monitors as their primary output devices. Those came much later. For many years the most popular I/O device was the teletype. What in the fuck is a teletype? Well, let me show you a flier from the 50’s that explains it all:

What is a teletype
To make a long story short, Teletypes were I/O devices that used a paper spool and dot-matrix style print-head as primary means of communicating data back to the user. It worked almost exactly like a typewriter, but one that could interpret commands and generate reports and do all kinds of other crazy stuff. It had the same limitations as it’s predecessor in that it had to feed paper in and move the print head to the right spot when starting a new line. So when you wanted your teletype to insert a line-break in the output, you had to send it a Carriage Return and Line Feed character. These characters would trigger the desired action.
The interesting caveat was that the time it took to move the print carriage from the extreme right edge of output to extreme left edge was rather long. It simply could not happen in single character time, which is why this why carriage return was commonly sent first, followed by line feed. In some slower teletypes even this was not enough, so programs usually sent carriage return, followed by several null/noop characters before the final line feed to give the machine enough time to reset itself to the right print position. At least this was the convention used by the DEC operating system.

Here is a picture of a dude using a teletype.
When monitors came along, there was a period of time where they existed side by side with teletype machines. By the time they replaced them completely the CR-LF convention was already so well established, and so commonly used there was just no reason to change it. IBM, and later Microsoft both chose to follow this convention in order to be able to be backwards compatible to the large number of DEC equipment still in use.
The Multics OS developed at Cambridge in early 70’s didn’t follow this convention. Because it was being created by scientists and engineers rather than corporate code jockeys it could eschew backwards compatibility and play with novel ideas. One of such ideas was chucking away the carriage return character altogether and just using a single line feed for encoding a line break.
You see, engineers like to optimize the shit out of things. The CR-LF combo was a glaring legacy wart that needed to be rubbed off. There was simply no reason for the CR character to exist. Since different teletype models needed different amounts of time to perform the carriage return function, it made sense to simply use a LF character, and then have it automatically trigger the carriage return action at the device driver level. This way programmers would not only be able to create smaller files (saving 1 byte per line break), but also would not have to worry about padding the space between CR and LF with null bytes to create the safety margin for slow teletypes.
Both Unix and Amiga operating systems were heavily influenced by Multics, and they adopted the same convention. Apple also took a page from the Multics book, but being the asshole hipster company they are (and always were) they decided to use the CR character rather than the LF for all their product lines. Fortunately, Apple has wised-up since then and returned to the Unix fold. Despite the fact it sometimes doesn’t feel like it, OSX is a fairly unremarkable Unix underneath the hood. It feels different because most of us are very much used to running Linux with the full-blown GNU toolkit installed on board. OSX doesn’t use the standard GNU tools, but rather an overlapping set of POSIX compliant unix tools – much the same as in BSD systems for example. Which is why some Linux scripts will fail in funny ways due to GNU related dependencies. Nevertheless being a Unix at heart it does use a single LF to indicate a line break.
These days Microsoft and Apple are fighting over the same market chunks, so there is not much competitive advantage for either of them to conform to the other guys standard. Microsoft is also very careful never to mention the free Linux and Unix offerings in public least people get the crazy idea to run a free operating system instead of one of their expensive ones. So the line ending differences between platforms are here to stay. Especially since they are not so difficult to work around. Most software that isn’t Notepad.exe can instantly recognize whether a file is using CR, LF or CR-LF convention and display it appropriately.
There’s also unicode LS (line seperator) and PS (paragraph seperator). :P
Relevant XKCD: http://xkcd.com/927/